Statistical learning begins where descriptive data analysis and statistical inference leave off. We are still interested in variation, uncertainty, and the relationship between sample and population, but now the focus is more sharply predictive: what structure can be learned from data so that new cases are handled well?
In one sense this is not new. Regression, estimation, and classification all have deep roots in older statistics. In another sense it is a genuine shift. Classical inference often asks whether a parameter exists, whether an effect is detectable, or how uncertain an estimate should be. Statistical learning asks, with the same mathematical honesty, how to build rules that generalise.
NoteIn this chapter
Distinguish explaining the sample from predicting new cases.
Use train/test splits and cross-validation as mathematical discipline, not ritual.
Compare regression and classification as different output spaces and loss stories.
Read overfitting as a mismatch between model flexibility and evidence.
5.1 Guiding examples
Temperature → sales (regression with generalisation)
Spam/not-spam (classification and evaluation)
TipRunning example: Alberta wildfire smoke and station PM2.5
This chapter’s job in the smoke story is generalisation. Build baselines and an evaluation split that cannot cheat:
Start with a persistence baseline (tomorrow ≈ today) and a seasonal baseline.
Use a time-aware split, and treat major smoke episodes as coherent events.
Compare regression (predict PM2.5) with classification (smoke-day yes/no).
Add calibration checks if you output probabilities for smoke alerts.
5.2 Prerequisite anchors
The key places to point backward are:
vol-06/01-probability-theory.qmd
vol-06/03-statistical-inference.qmd
vol-06/04-data-analysis.qmd
vol-07/probability/02-mathematical-statistics.qmd
5.3 From inference to prediction
Suppose we fit a line to data. In a classical setting we may focus on confidence intervals, significance, and the interpretation of coefficients. In a learning setting we ask an additional question: if a fresh case arrives tomorrow, will the fitted relationship make a useful prediction?
That question changes the centre of gravity.
The model is no longer judged only by how elegantly it explains the sample in hand. It is judged by its performance on unseen data drawn from the same or a similar process. This is why the word generalisation becomes central. A model that memorises the sample without capturing durable structure has learned very little.
A concrete illustration. Suppose we have 60 observations of daily temperature x and ice-cream sales y. Fitting a line yields a slope and an intercept. In an inference frame, we would report the slope, its standard error, and a p-value testing whether the slope is zero. Those answers are about the sample. In a learning frame, we split the data: 50 points for fitting, 10 held out for evaluation. We fit on the 50, then predict the 10, and measure mean absolute error on cases the model never saw. These are different questions. They are compatible — a well-identified parameter tends to also predict well — but they are not the same question.
The held-out evaluation is harder to pass. A coefficient can reach conventional significance thresholds with modest sample sizes, but held-out prediction error is disciplined by the true variability of new cases. This is why prediction-focused evaluation is often more demanding than significance testing, especially when the number of features approaches the number of observations.
5.4 Regression and classification
Two foundational supervised tasks dominate the chapter.
Regression predicts quantities on a numerical scale: demand, rainfall, waiting time, fuel use, growth, cost, concentration. The output is continuous or at least ordered enough that numerical distance matters.
Classification predicts categories: spam or not spam, healthy or diseased, approved or rejected, species A or species B. Here the output space is discrete, and what matters is not the numerical distance between labels but the quality of the decision or the probabilities attached to the classes.
These are not merely two software modes. They are two mathematical settings with different losses, different diagnostics, and often different notions of success.
5.5 Residuals, likelihood, and fit
In regression, one of the first objects to study is the residual:
r_i = y_i - \hat{y}_i.
Residuals remind us that the model does not meet the data exactly. They carry information about bias, noise, outliers, and missing structure. A clean-looking fit in a plot may still hide patterned residuals, and patterned residuals are a warning that something systematic has been missed.
A parallel idea in probabilistic modelling is likelihood. Instead of asking only how far a prediction lies from the observed value, we ask how plausible the data would be under the model. That shift becomes especially important in classification and in models that output full probability distributions rather than single-point guesses.
5.6 Overfitting and underfitting
A model can fail by being too rigid or too flexible.
If it is too rigid, it misses real structure. This is underfitting. If it is too flexible, it starts adapting to accidental quirks of the training sample. This is overfitting.
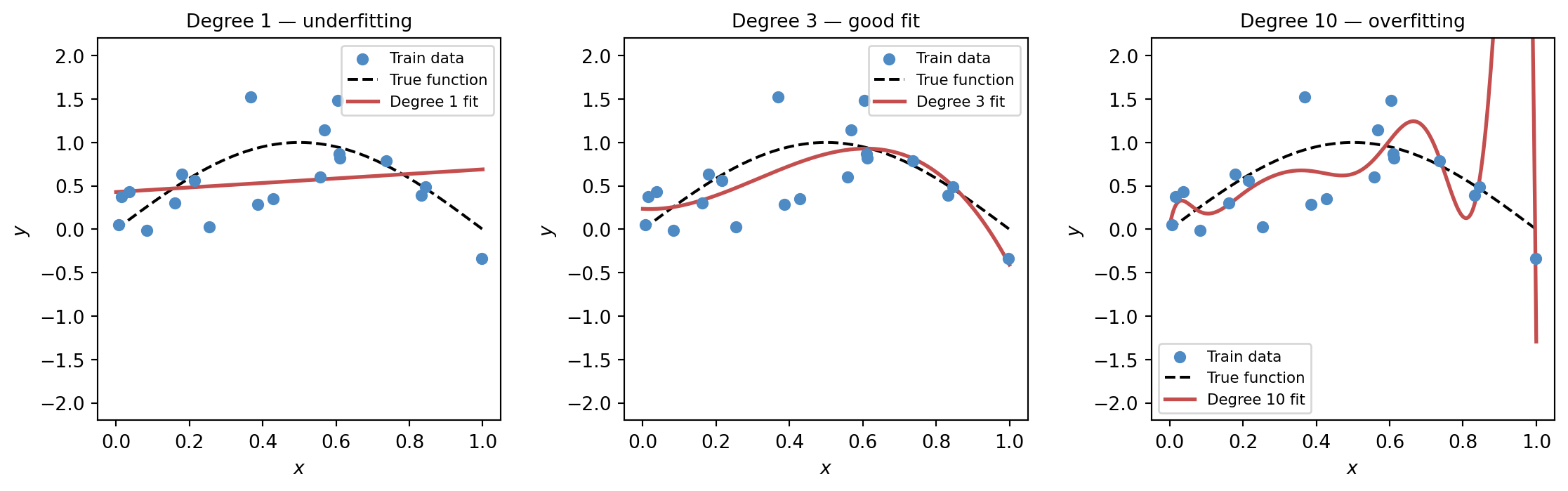
To make this concrete, consider fitting polynomial curves to noisy data from the function y = \sin(\pi x) + \varepsilon, where \varepsilon \sim \mathcal{N}(0, 0.3^2). With a degree-1 polynomial (a straight line), the model cannot follow the curve’s shape at all. It misses the genuine nonlinearity. With a degree-3 polynomial, the curve bends in the right directions and recovers the main signal. With a degree-10 polynomial, the model has enough freedom to pass through or near every training point — but between those points it oscillates wildly. On new data drawn from the same distribution, the degree-10 model performs far worse than the degree-3 model, even though it fits the training set better.
The language can sound informal, but the underlying issue is exact: how much of the variation in the data reflects durable signal, and how much is local noise?
Figure 5.1: Three polynomial fits to the same 20 noisy observations from y = \sin(\pi x) + \varepsilon. Degree 1 underfits (too rigid). Degree 3 fits well (right amount of flexibility). Degree 10 overfits (memorises noise).
5.7 Bias-variance tradeoff
The underfitting-overfitting tension has a precise mathematical form. For a given test point x_0, the expected squared prediction error decomposes as
Bias measures how far the average prediction of the model family is from the true value. A straight line fitted to sine data will always miss, no matter how much data we collect — that gap is systematic bias.
Variance measures how much the fitted model changes when the training set changes. A degree-10 polynomial fitted to 20 points is highly sensitive to which 20 points we happened to draw. Small changes in the sample produce wild swings in the fitted curve.
Irreducible error\sigma^2 is the noise in the data itself, independent of the model.
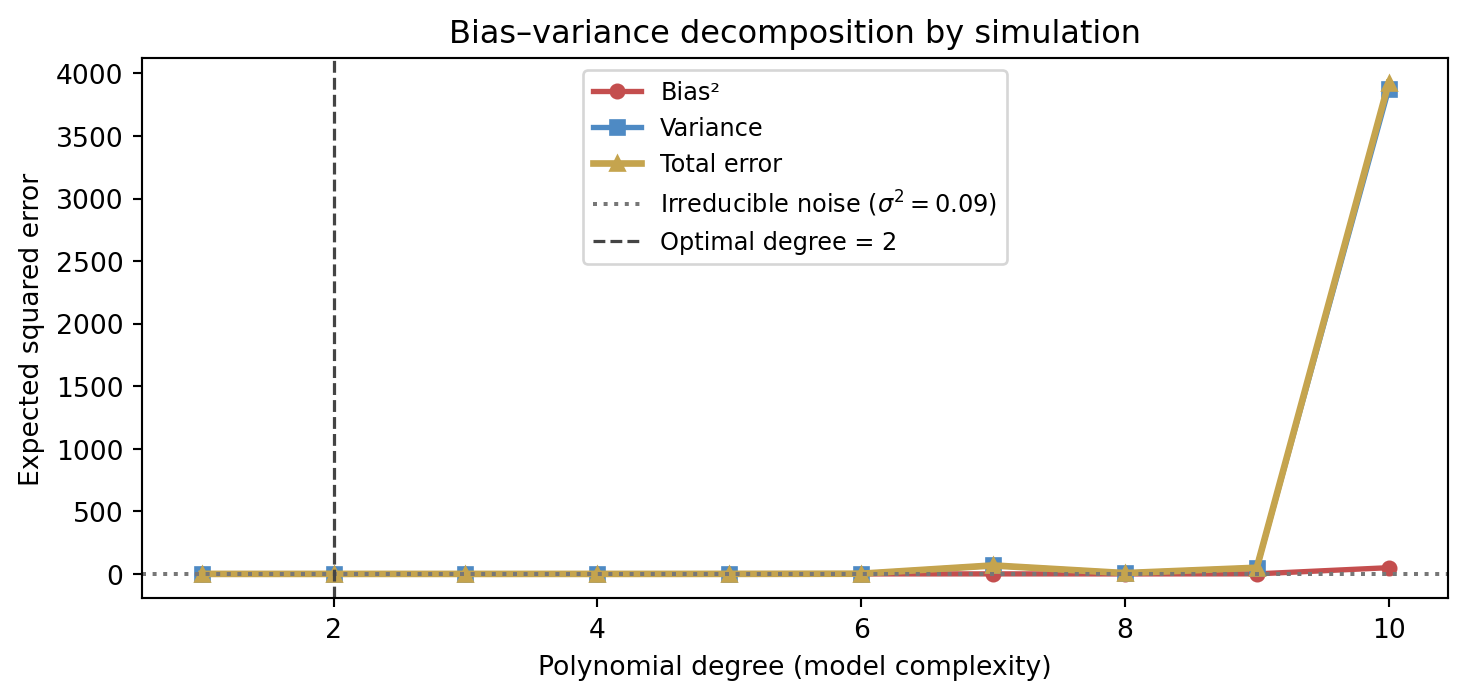
Simple models have high bias and low variance. Complex models have low bias and high variance. The optimal complexity minimises their sum (plus the fixed noise floor). This is not a metaphor — it can be computed by simulation.
The figure below estimates all three quantities by generating many training sets from the same process, fitting polynomials of each degree, and averaging. No external library is needed: the decomposition is computed directly from the simulation.
Figure 5.2: Bias–variance decomposition estimated by simulation across polynomial degrees 1–10. The optimal degree minimises total expected error. Irreducible noise sets the floor.
5.8 Regularisation as disciplined simplification
One of the healthiest ideas in statistical learning is regularisation.
Instead of asking the model only to fit the data well, we also ask it to remain simple in a chosen sense. The simplicity might mean smaller coefficients, fewer effective degrees of freedom, smoother functions, or less extreme decision boundaries.
That is not a cosmetic preference. It is a mathematical way of expressing the belief that wild explanations of limited data should be treated with suspicion.
Ridge regression adds a penalty on the squared magnitude of the coefficients. For a linear model with parameters \beta, the penalised objective is
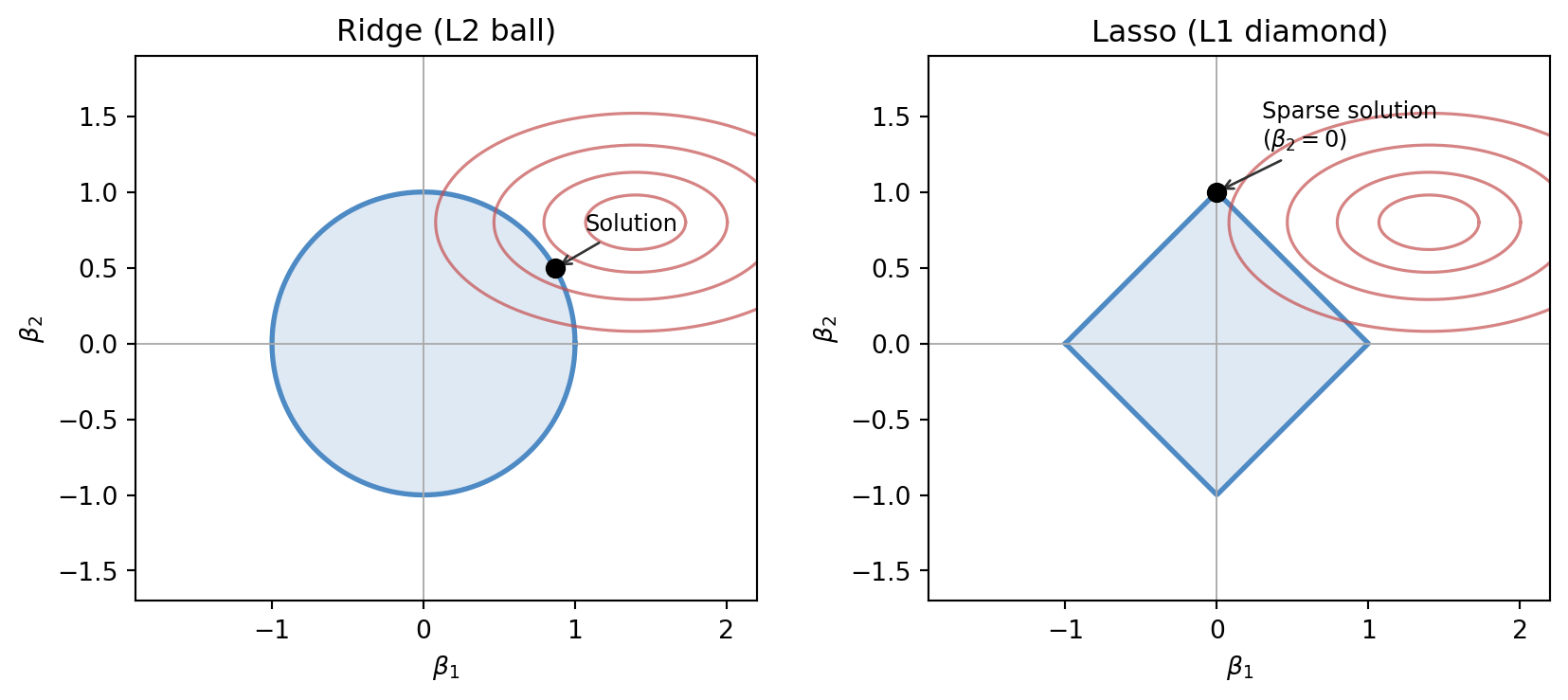
where \lambda \geq 0 controls the strength of the penalty. This has a closed form: the ridge estimator is \hat{\beta} = (X^\top X + \lambda I)^{-1} X^\top y. As \lambda increases, the coefficients shrink toward zero but none are exactly zeroed. The constraint set in coefficient space is a sphere (L2 ball).
Lasso regression replaces the squared-norm penalty with an absolute-value penalty:
The constraint set is now a diamond (L1 ball). The geometry of the diamond has corners on the coordinate axes. When loss contours meet the constraint set at a corner, the solution has an exact zero coefficient. This is why lasso produces sparse solutions — it effectively selects features — while ridge does not.
The figure below shows this geometry. On the left, an L2 ball and elliptical loss contours; the optimum lies on the smooth surface of the ball, not at a special point. On the right, an L1 diamond; the elliptical contours are more likely to contact the diamond at a corner, where one coefficient is exactly zero.
Figure 5.3: Regularisation geometry. Left: ridge (L2) — smooth ball, solution at a generic point on the boundary. Right: lasso (L1) — diamond, solution at a corner, forcing one coefficient to zero.
Later chapters will show regularisation appearing in many forms — weight decay in neural networks, early stopping, dropout — but its spirit is already visible here: fitting is never the whole story.
5.9 A modelling lens for the rest of the book
Statistical learning sits in the middle of the book because it teaches a habit that the later AI chapters depend on. We learn to ask:
what is the prediction task?
what kind of uncertainty is present?
what structure is signal and what structure is noise?
what constraints keep the model honest enough to generalise?
These questions will return in optimisation, representation learning, probabilistic modelling, and neural networks.
5.10 Optional viewpoints
quality control
sports or environmental forecasting
baseline predictive systems in operations
TipWhat to try
Adjust POLY_DEGREE from 1 to 12 to see how training and validation error diverge as complexity grows. Change LAMBDA (the regularisation strength) to see how penalising large coefficients can recover better validation performance at high degree.
MSE decomposition. Show analytically that \mathbb{E}[(y - \hat{y})^2] = \text{Bias}^2 + \text{Variance} + \sigma^2 by expanding y = f(x) + \varepsilon and \hat{y} = \hat{f}(x), where \varepsilon has mean zero and variance \sigma^2 and is independent of \hat{f}.
Polynomial degree selection. For a synthetic dataset of your choice drawn from a nonlinear function with noise, split the data 70/30 and compute validation MSE for polynomial degrees 1 through 8. Plot the curve and identify the degree that minimises validation error. How does this degree change if you double the noise level?
Ridge estimator. Starting from the penalised objective J(\beta) = \|y - X\beta\|^2 + \lambda\|\beta\|^2, differentiate with respect to \beta, set to zero, and derive the ridge estimator \hat{\beta} = (X^\top X + \lambda I)^{-1} X^\top y. Show that when \lambda > 0 the matrix X^\top X + \lambda I is always invertible, and explain why this makes ridge more numerically stable than ordinary least squares when features are nearly collinear.
Regularisation path. Describe what happens to the ridge coefficients as \lambda \to 0 and as \lambda \to \infty. Then answer the same question for lasso. In the lasso case, which coefficients reach zero first as \lambda increases, and what does this tell us about feature selection?